
はじめに
この記事ではRancher Meetup #01 in Osakaにて共有した、Data Processing Platform(DPP)の環境構築方法をご紹介します。
構築に成功したら、カスタマイズして自分のDPPを作りましょう!
AWS上でホストを作りたいと考えている方は、こちらのリポジトリのTerraformを使用することができます(try-dppブランチ)。
使い方については、前回の記事「RancherにTerraform + AWSでホスト(RancherOS)を自動追加」を参考にしてください。
前提条件
全てを細々と解説すると記事が長くなりすぎてしまうので、以下を準備してあるものとします。
- Rancher Serverが既に稼働している
- CattleのEnvironmentが新規作成してある
- ここのDPPのスタックを展開します
- Environmentの環境APIキーを作ってある
- このAPIキーを使ってスタックを展開します
- Environmentにホストが5台(CPU: 4 core, Memory: 32GB x 5, AWSのi3.xlarge相当)登録されている
- Terraformをインストール済み
- JSONツールの jq をインストール済み
- Zeppelinのセットアップに使います
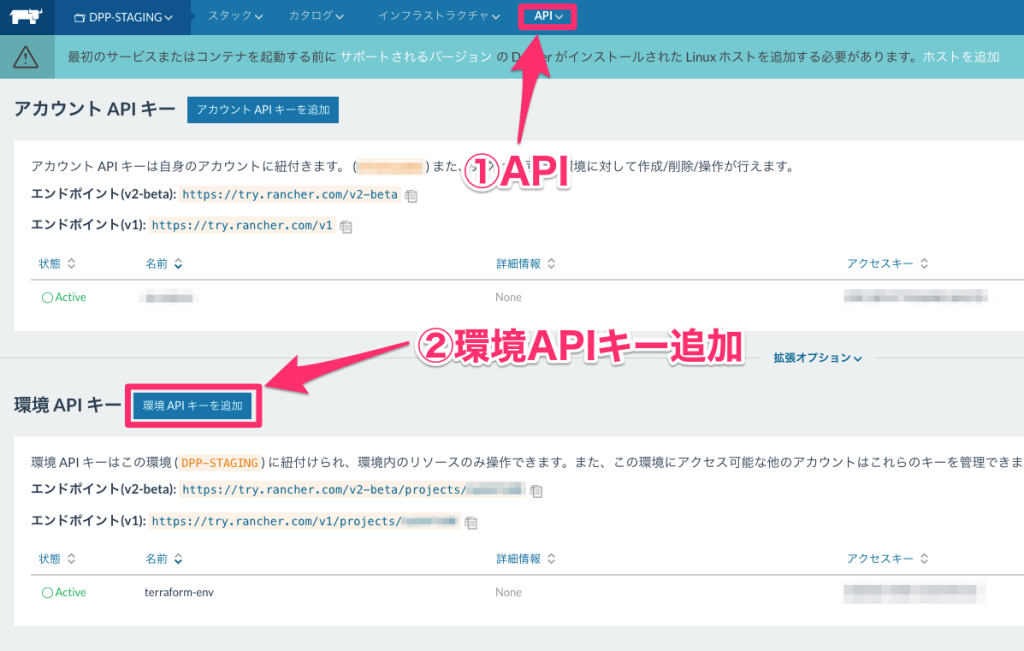
Environmentの環境APIキーについて
Rancher Serverから以下の手順で作成できます。
環境APIキーを使うことで、そのEnvironmentに対してAPI経由でリソースを作ることができます。
ホストにラベルを付与
今回の検証ではJMeterを使うのですが、検証対象とJMeterが同じホスト上で動くのは嫌なので、5つあるホストのうち2つはJMeter専用のホストにします。
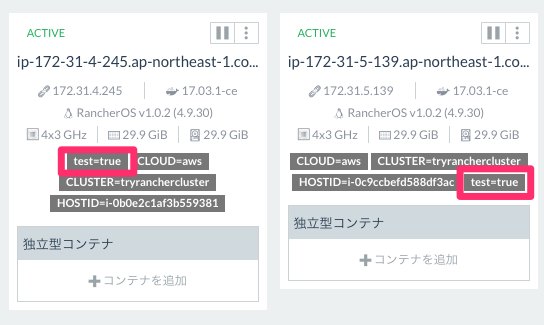
JMeterのサービス側スケジューリングのルールで設定していますが、ホストにtest=trueというラベルが付いていることを条件にしている為、このラベルを2つのホストに付与しておきます。
ホストの編集を開いて
以下のようにラベルを追加します。
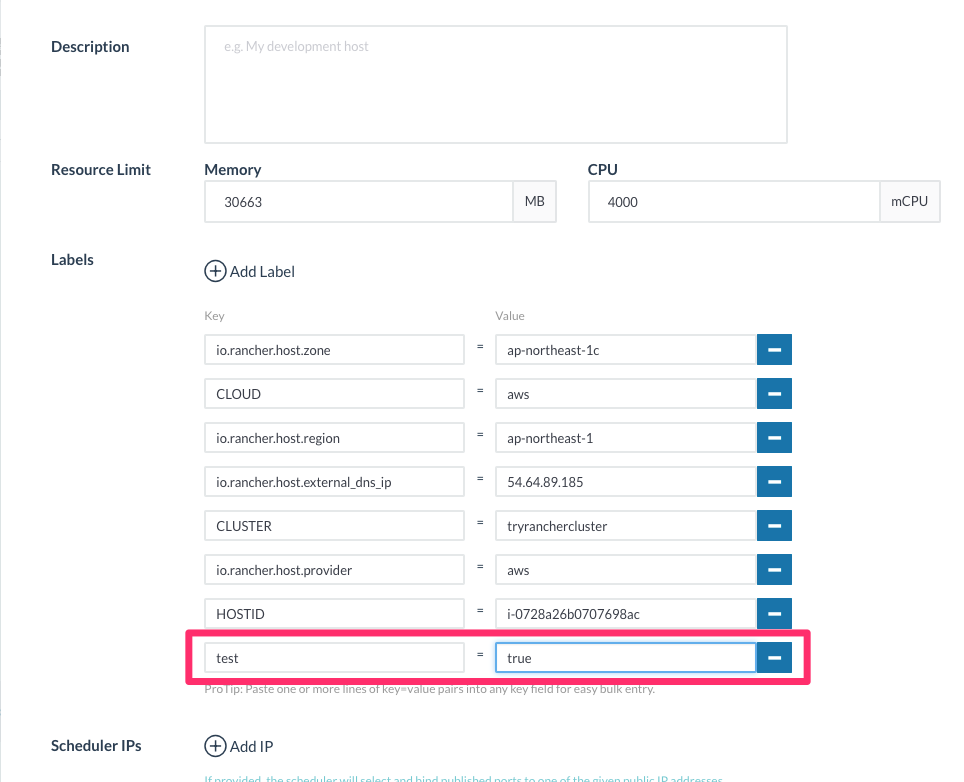
これを2ホスト分やっておきます。
正常にラベルが付与できるとUIでも確認ができます。
スタックを展開
それではEnvironmentにスタックを展開しましょう。
スタックの一式はGithub(supersoftware/dpp)にアップしていますので、cloneして適宜ご利用ください。
スタックの構成としては以下の通りです。
- cassandraスタック
- Cassandraのコンテナ群
- jmeterスタック
- JMeterのMasterとSlaveコンテナ群
- kafkaスタック
- KafkaのBrokerとManagerのコンテナ群
- lbスタック
- ロードバランサのコンテナ群
- minioスタック
- Minioのコンテナ群
- openvpnrancherlocalスタック
- OpenVPNのRancher Localユーザ用のコンテナ群
- prometheusスタック
- Prometheus + Graphana関連のコンテナ群
- sparkスタック
- Spark Driver, Master, Worker, Zeppelinのコンテナ群
- webスタック
- AkkaによるWeb-APIとNginxによるAngularの配信に関連するコンテナ群
- zookeeperスタック
- Zookeeperのコンテナ群
これを1つ1つEnvironmentに作っていくのは大変です。
Rancher CLIを使うこともできますが、TerraformのProviderにはRancherも用意されていて、一括でStackを展開できます。
今回はTerraform(v0.9.6)を使うことにします。
terraform/ディレクトリ内にapply-all.shがあり、これを実行することでEnvironmentにすべてのスタックが展開されます。terraform apply時に必要になるのは以下の情報です。
rancher_url- Rancher ServerのURL(例えば
https://try.rancher.com)
- Rancher ServerのURL(例えば
rancher_access_key- 環境APIキーのアクセスキー
rancher_secret_key- 環境APIキーのシークレットキー
rancher_environment_id- EnvironmentのID(※)
※EnvironmentのIDについて
一例として、APIメニューの以下の場所でEnvironment IDは確認できます。

apply-all.shが完了したら、Environmentに上記のスタックが全て展開されているのが確認できるかと思います。
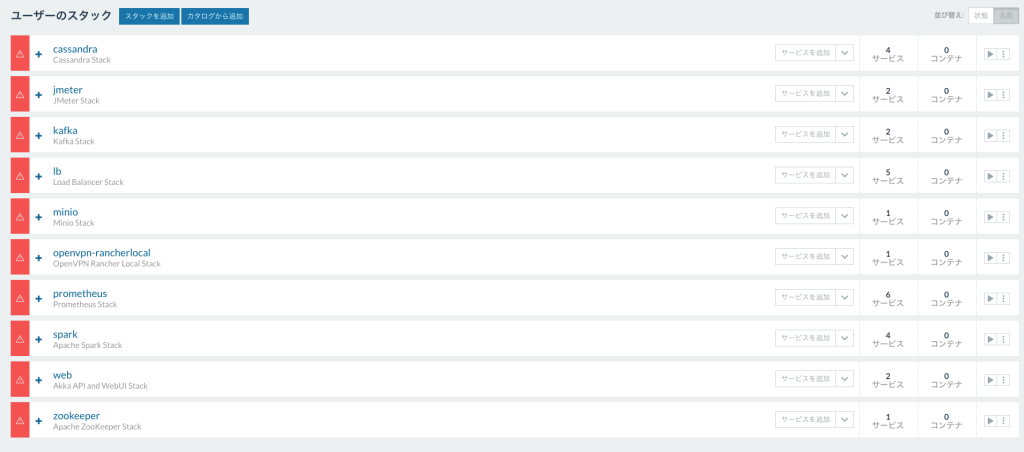
※ なぜterraform applyじゃないのか?
terraform applyから一括でスタックを展開したいところですが、lbスタックが他のスタックに入っているサービスと依存関係がある為、lbスタックだけは全てのスタックが展開されたあとに展開したいからです。
今のところterraformにスタック間の依存関係を調整する機能が無く、やむを得ずスクリプトでラップしています。
サービス開始
スタックの準備ができたのでサービスを開始していきます。
まずはsparkとopenvpnrancherlocalスタック以外をサービス開始します。
Minioにリソースをアップロード
順次コンテナが展開されていくかと思いますが、lbとminioスタックが青くなったらさっそくminioに接続しましょう。
3台あるホストのうち、どれかのhttp://<Public IP>:9000にアクセスすることで、minioのGUIが閲覧できます。
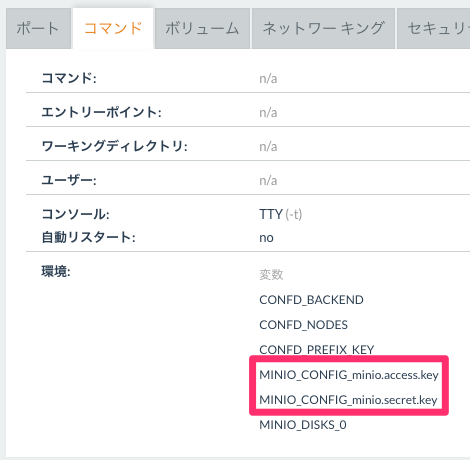
Access KeyとSecret KeyについてはminioコンテナのMINIO_CONFIG_minio.access.key MINIO_CONFIG_minio.secret.keyの値で設定してあるものになります。
ログインができたらさっそくbucketを作ります。
新規バケットを作成し、distという名前にしてください(今回のアプリケーションがこのパスを見ているのでdistという名前にしているだけです)。
バケットはすぐに作られるので、次にJMeterで使うjmxファイルと、Sparkアプリで使うjarファイルをアップロードします。
それぞれdppリポジトリ内のjmeter/boc.jmxと、spark/kafka-spark-cassandra-assembly-1.0.jarに格納してあります。
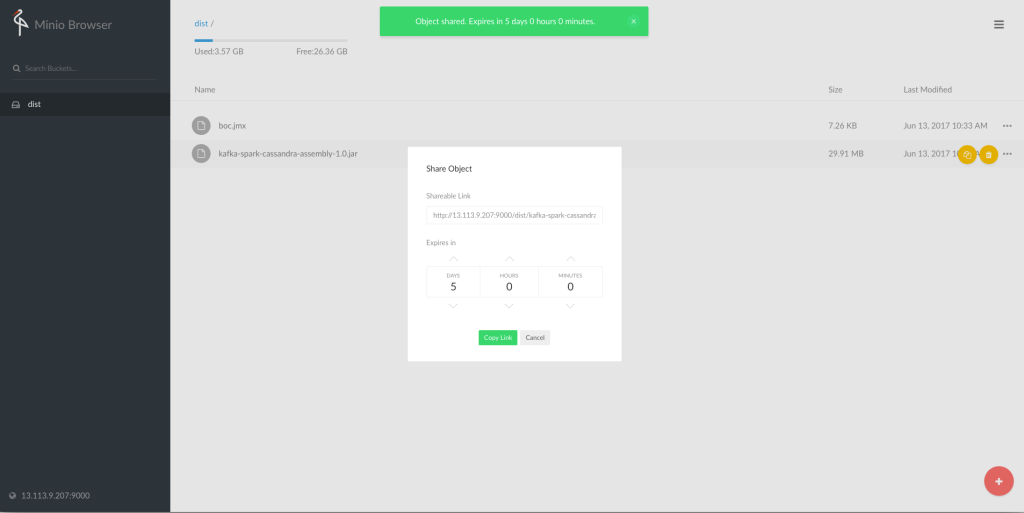
アップロードが完了したら、boc.jmxは後からJMeterのMasterからダウンロードしたいので公開用のURLを生成しておきます。
このURLはあとで使うのでメモっておいてください。
Sparkスタックの起動・設定
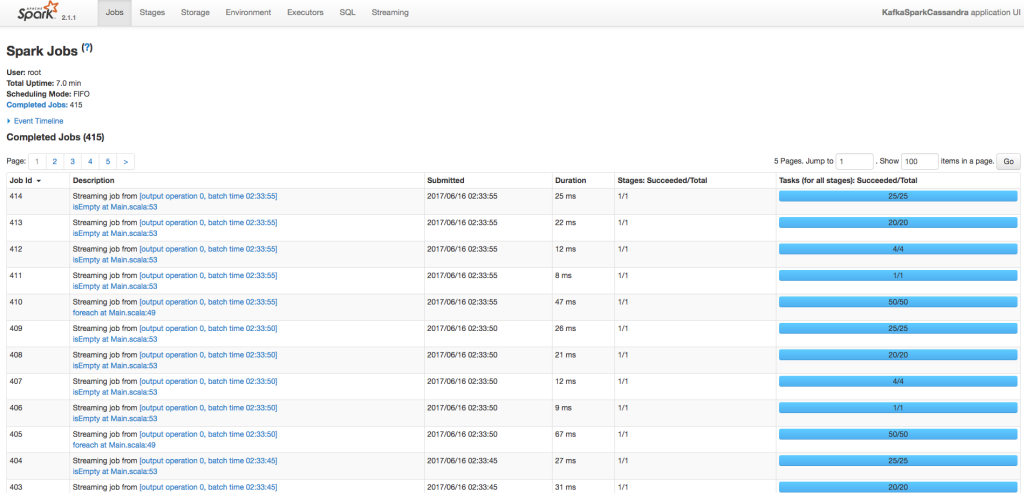
jarの準備が完了したので、次は保留していたSparkスタックを開始します。開始後しばらくしたらSpark UI(http://<Public IP>:4040)にアクセスできるようになります。
そして、Zeppelin(http://<Public IP>:8080)にもアクセスできることが確認できたら、Zeppelinの設定をします。
クローンしたリポジトリのspark/setup-zepplin.shを実行してください(sparkディレクトリの中で実行してください)。
Zeppelinのエンドポイントには<Public IP>:8080(http://は不要!)を設定します。complete!が表示されたら設定完了です。このシェルで行っていることは
- Zeppelinにノートブックをインポート
- Cassandra Interpreterを設定
- Spark Interpreterを設定(spark-cassandra-connectorというライブラリも使ってるので
dependenciesに追加)
になります。
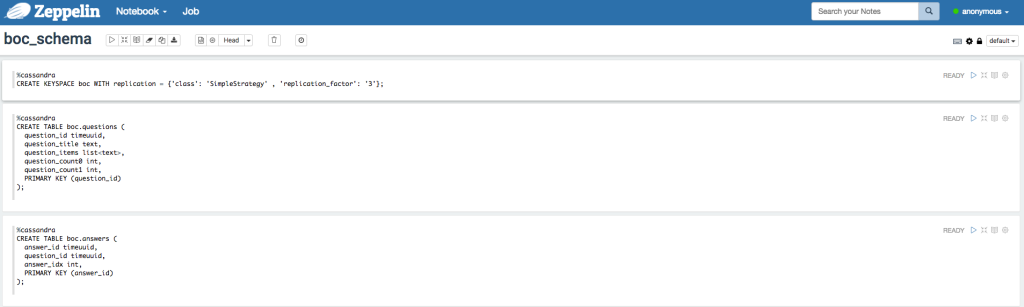
Cassandraのスキーマ作成
Zeppelinの準備もできたのでCassandraのスキーマをZeppelin経由で作ります。
Zeppelin(http://<Public IP>:8080)に接続してboc_schemaノートブックを開きます。
そのノートブックの上段3つを実行します(CREATE KEYSPACEがエラーになることがありますが、keyspace自体は作られているのでいったん無視してください)。
bockeyspaceの作成boc.questionsテーブルの作成boc.answersテーブルの作成
をそれぞれ行っています。
API経由でCassandraにデータ投入
それでは疎通確認もかねてAPI経由でCassandraにデータを投入してみましょう。http://<Public IP>/api/questionsエンドポイントに対して
{
"items": ["Beef", "Chicken"]
}というJSONを送ってみてください。
正常に動作していればCassandraにデータが投入されます。
Zeppelinのboc_analyzeノートからboc.questionsに対してクエリを投げれるので確認します。
ここで生成されているquestion_idは後程 JMeter で使いますのでメモっておきます。

集計処理を設定
今回の構成では集計処理はZeppelinのジョブを定期実行することで実現しています。boc_analyzeノートを開きジョブの周期実行を設定します。
これで1分おきに集計処理が実行されるようになります。
Web UIの確認
それではhttp://<Public IP>にアクセスしてWeb-UIを表示しましょう。
正常に動いていれば先程投入したデータが一覧に出てくるはずです。
アイテムをクリックすると以下のような詳細画面が表示されるはずです。
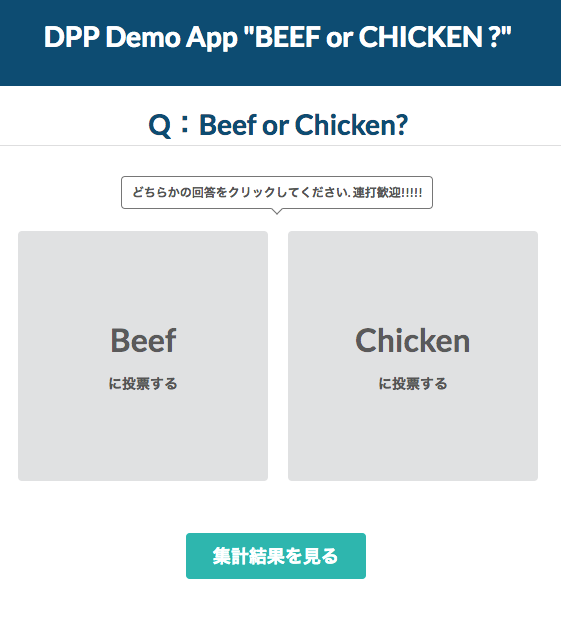
さて、適当にここで投票ボタンを連打して投票してみましょう。
このリクエストはAkka -> Kafka -> Spark Streaming -> Cassandraと流れていき、1分後にはZeppelinの集計処理が実行されて集計結果が再びCassandraに反映されます。
全て正常に動いていれば以下のように集計結果が表示されるはずです。
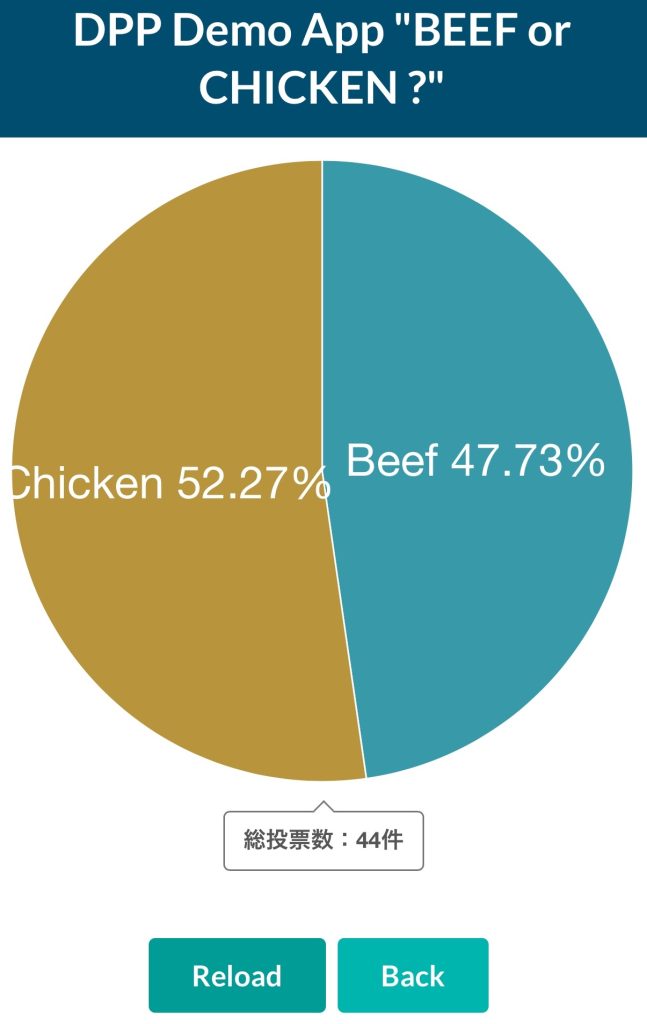
一連の流れはこれでOKです。
では最後にJMeterで負荷をかけてみましょう。
JMeterで負荷テスト
それではJMeterスタックのMasterコンテナに入ってJMeterを実行してみましょう。
まずはminioの先程メモったURLからboc.jmxをwgetしてきましょう。
wget -O boc.jmx "<minioの公開URL>"そしてJMeterを実行します!
このときの引数としてQUESTION_IDを渡しているのですが、ここには先程メモしたquestion_idを入力します。
jmeter -n -t boc.jmx -Rjmeter-slave-1,jmeter-slave-2,jmeter-slave-3,jmeter-slave-4,jmeter-slave-5,jmeter-slave-6 \
-GHOST=web.lb -GQUESTION_ID=<さっきメモったquestion_id> -GTHREAD_NUM=400 -GRAMP_UP=300 -GLOOP_CNT=417
うまくいけば6台のスレーブが動き始めます。
概ね5分で100万リクエストを投げる設定になっています。
負荷をかけたい量に応じてTHREAD_NUM, RAMP_UP, LOOP_CNTを設定しましょう。
以下はもう少し負荷の量を増やしたときのSpark Streamingのグラフです。
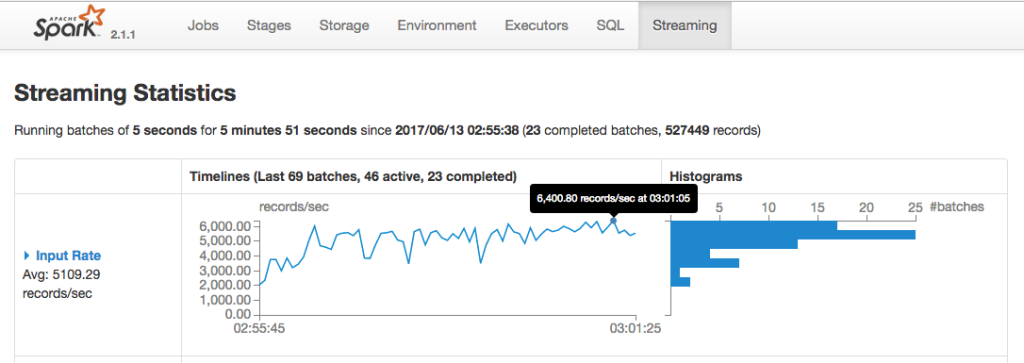
おわりに
以上で検証用のDPP環境の構築完了です!
ここからコンテナを差し替えて自分流のDPPを作ってみましょう!
以下の図の通り
spark/driverがspark-submitしているjarspark/zeppelinの集計ロジックweb/apiのREST-API部分web/ui画面
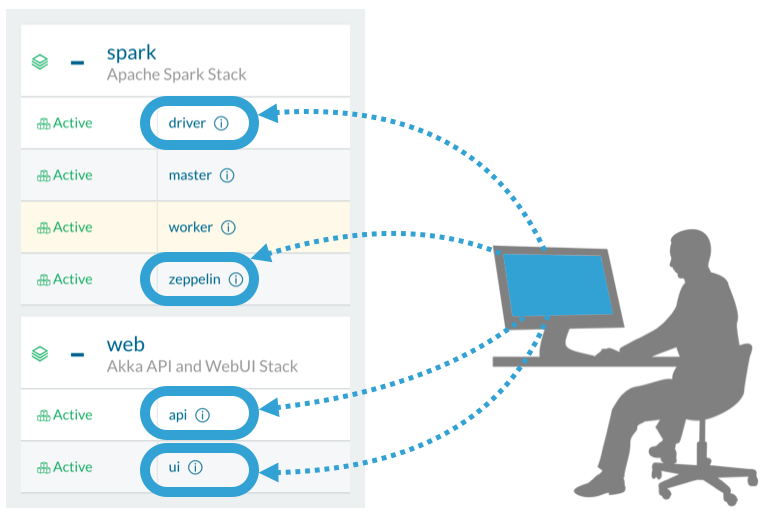
を差し替えることで比較的容易に自分流のDPPにカスタマイズが可能です。




