はじめに
何かサービスを作る際、検索機能を盛り込むケースは非常に多いと思います。
昨今では当たり前となったこの検索機能ですが、これががなかなか厄介な代物だったりします。
例えばRDBを使っている場合、中間一致や後方一致を可能にすると、インデックスが使えずにパフォーマンスや負荷に影響が出てしまったりと一筋縄にはいきません。
そこで、Apache SolrやElasticsearchといった全文検索の導入が有力な選択肢となります。
AWSでは全文検索サービスとして以下の2種がリリースされています。
- AWS CloudSearch
- AWS OpenSearch Service(旧AWS Elasticsearch Service)
どちらも似たような機能のサービスですが、前者はカスタマイズ性が低いぶん手軽に利用することができます。
逆に後者は、カスタマイズ性と自由度の高い検索機能の実装が可能です。
ということで今回は、入門に最適なAWS CloudSearchの設定を行い、実際に使っていきたいと思います。
構築
それでは早速環境を作りましょう。
前提として検索対象とするデータが必要です。今回は青空文庫のCSVデータをお借りします。
作家別作品一覧:http://www.aozora.gr.jp/index_pages/person_all.html
utf8形式のCSVファイルをダウンロードしたら、少し手を加える必要があります。
まずヘッダ行を適当な英語にしておきます。
日本語のヘッダ名だと解析時に列名が正しく解釈されないようでした。
もう1点、日付の形式を修正する必要があります。
若干雑ですが、以下のように一括置換しておきます。
(\d+)-(\d+)-(\d+) → \1-\2-\3T00:00:00Z
データの準備ができたら、AWSのコンソール上でCloudSearchへアクセスし、「Create New Search Domain」を選択します。
作成画面が開くので適当なドメイン名を入力します。
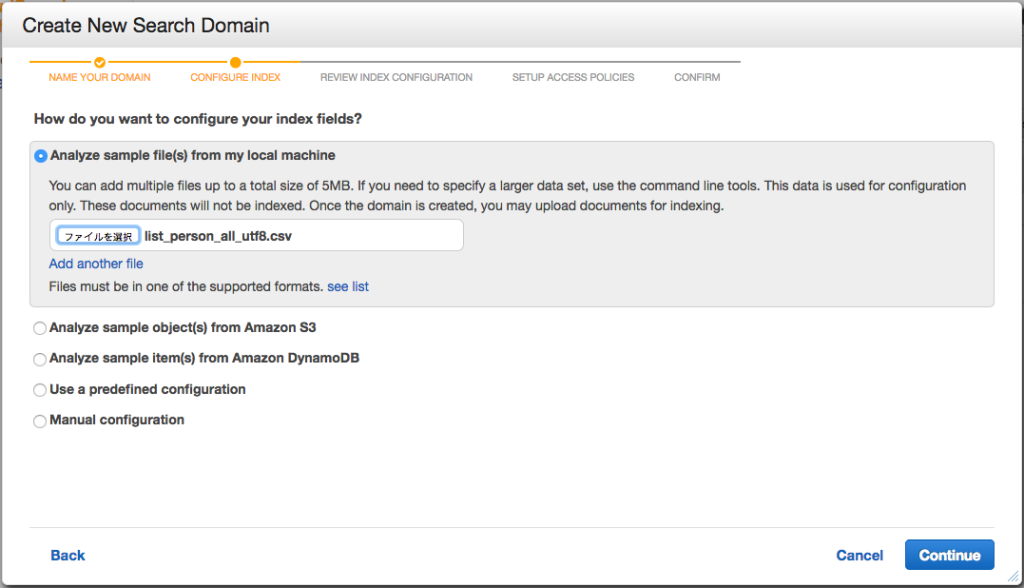
次に検索インデックスを設定するためにサンプルをアップロードします。
今回は手元にデータとなるファイルがあるので、一番上を選択し、用意しておいたCSVファイルを指定します。
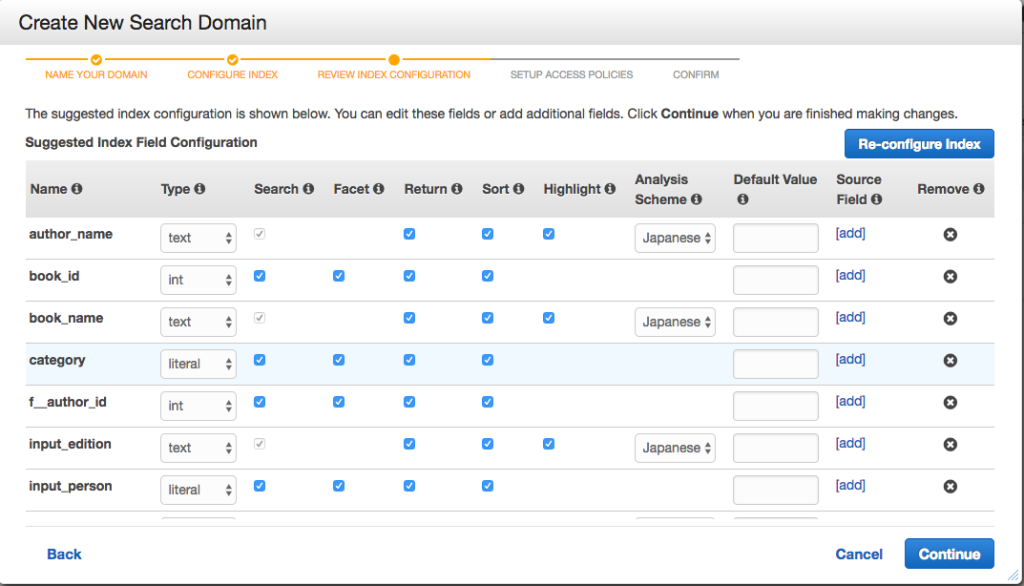
少し待つと解析結果として設定内容が表示されますので、データ型や言語を適切に修正します。
今回はお試しということもあり、ざっくり以下のように修正しています。
・author_name(著者名)を text に変更
・status_start_date(状態の開始日)を date に変更
・その他、言語が English の項目を Japanese に変更
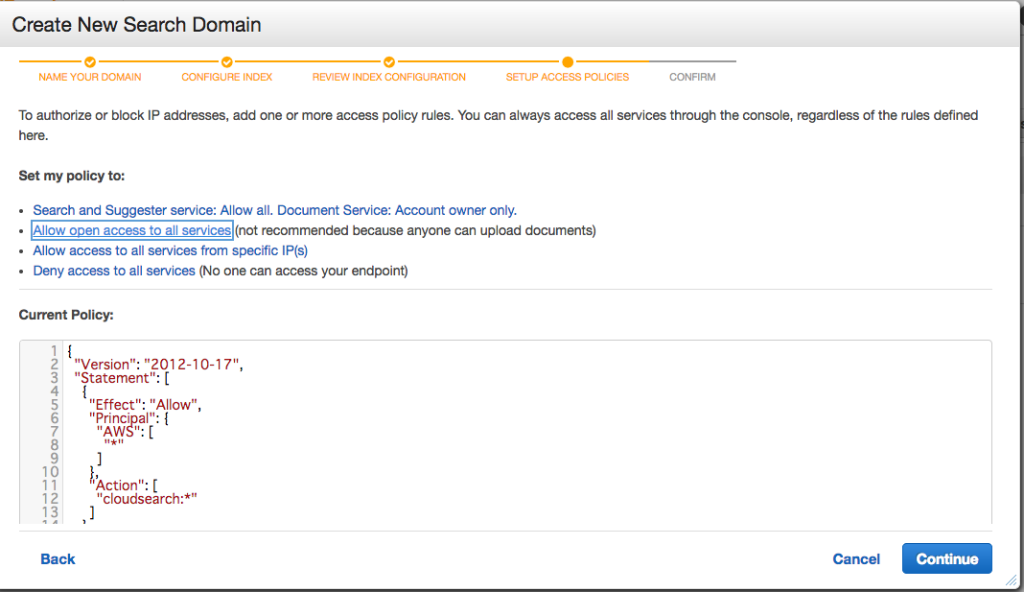
最後にアクセス制御を設定します。
本来は必要最低限にすべきですが、後からでも変更できるので、一旦は自由にアクセスできるようにしてしまいます。
上から2番目のリンクをクリックすると、自動的にそのようなポリシーが設定されます。
あとは内容を確認して完了です。
作成に10分前後かかるようなので、しばらく置いておきましょう。
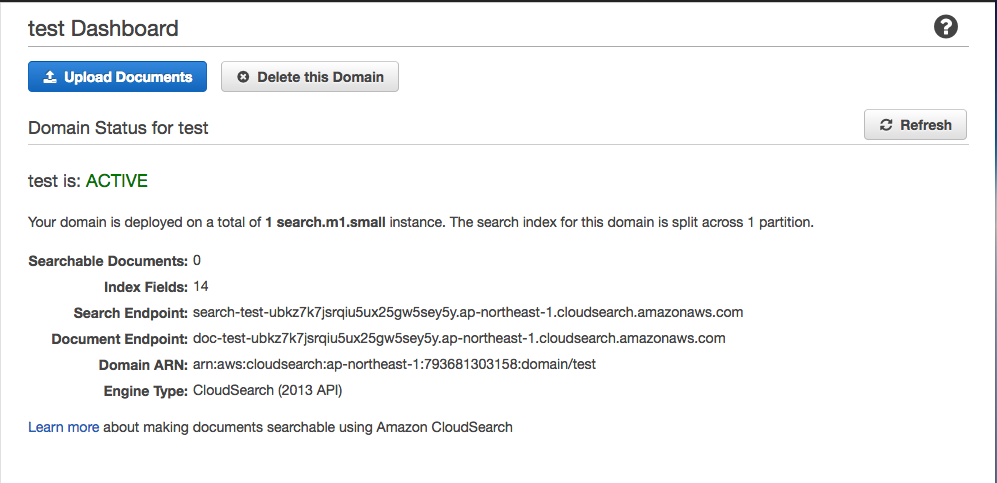
上の画像のようにステータスがActiveになったら、いよいよデータの投入です。
「Upload Documents」を選択します。
※Activeになっても直後はデータのアップロードボタンが非活性だったりしたので、余裕を持って待つのが吉です
サンプルのアップロードと同じように、一番上を選択し、ダウンロードしたファイルを指定します。
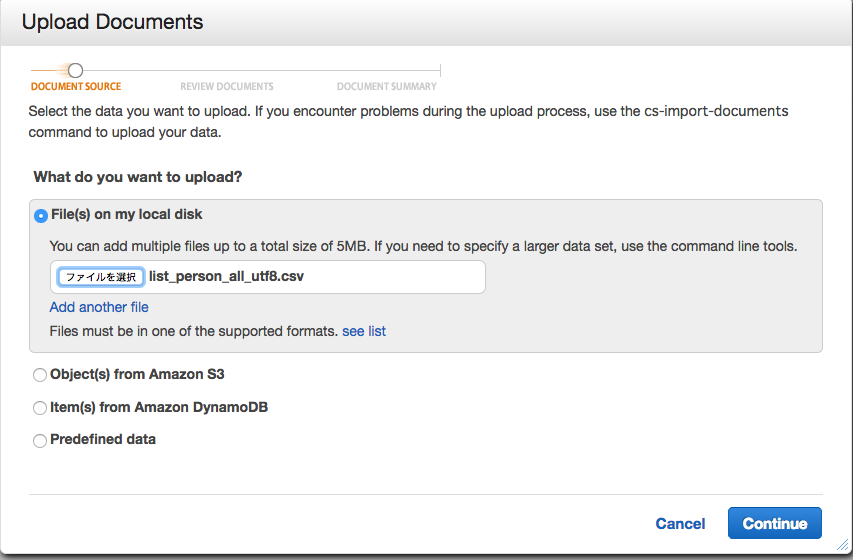
内容を確認し、問題がなければ完了です。
完了画面でエラーが出ている場合はメッセージを確認してください。
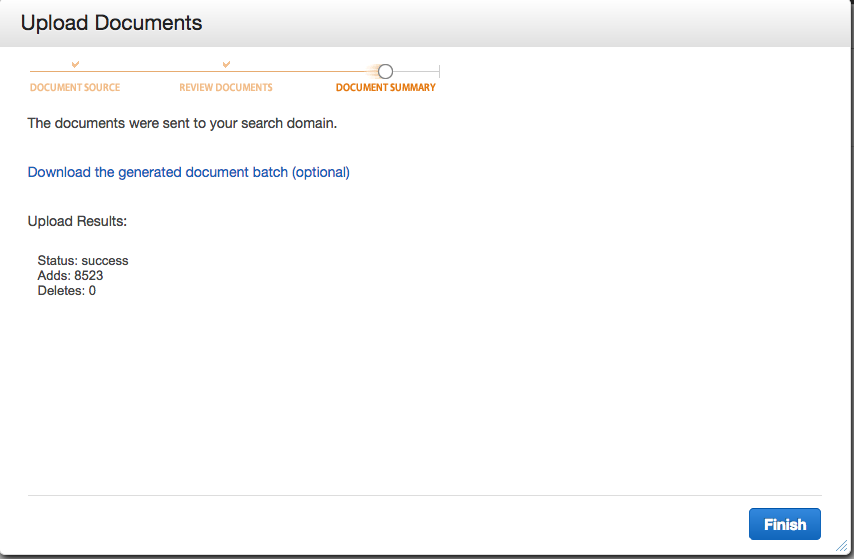
8500件ほどのデータが投入できたようです。
反映されるのを少し待ってから、実際に検索してみます。
左側のメニューから「Run a Test Search」を選択すると、検索を試すことができます。
適当な条件で検索してみましょう。
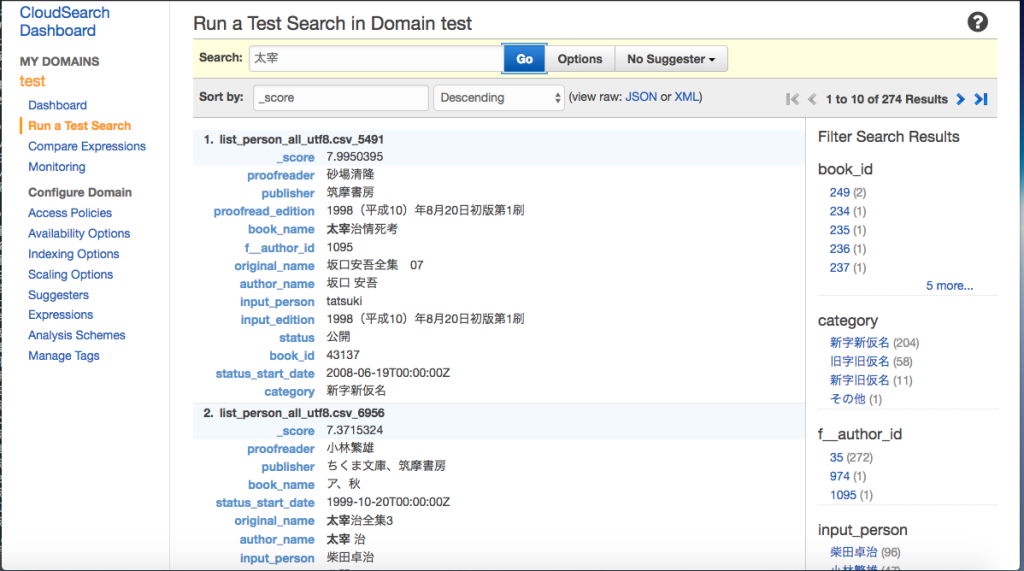
274件該当と、無事検索ができてそうです。
検索結果内の太文字の部分が条件にマッチした部分のようで、スコアの高かった順に表示されていますね。
右側にも色々なフィルタが用意されていたりと、この時点でだいぶリッチな検索を行えそうです。
おわりに
手探りながら、CloudSearchの使い方を簡単に解説させて頂きました。
もう少し使いこなせれば、実装の幅も大きく広がりそうなので、引き続き使っていきたいですね。
次回はRuby等のアプリケーション側から実際に今回構築した全文検索を使ってみたいと思います。









